利用视频识别声音提取文字的方法和应用(视频声音识别技术实现语音转文字的关键技巧与应用案例)

随着人工智能技术的快速发展,视频识别声音并提取文字的能力逐渐成为了现实。通过将视频中的声音转换为文字,我们可以实现语音内容的可视化,提高文档处理效率,同时也为听力障碍人群提供了更多的便利。本文将介绍一些视频识别声音并提取文字的方法和应用,帮助读者更好地理解这一技术并应用到实际场景中。
一、视频声音转文字技术简介
通过对视频中的声音进行分析和处理,可以将声音转换为相应的文字信息。这种技术基于语音识别算法和视频处理技术,可以准确地将视频中的语音转换为文字。
二、基于机器学习的声音识别算法
机器学习是实现声音识别的核心算法之一。通过训练大量的语音数据,机器可以学习到声音的特征,并将其转换为相应的文字信息。
三、深度学习在视频声音识别中的应用
深度学习是近年来非常热门的人工智能算法,它在视频声音识别中也有广泛的应用。深度学习算法可以更准确地提取声音的特征,并将其转换为文字。
四、视频声音识别技术的应用案例
视频声音识别技术可以应用于多个领域,例如会议记录、视频字幕生成、视频内容检索等。本节将介绍一些典型的应用案例,帮助读者更好地理解该技术的实际应用价值。
五、视频声音识别技术的挑战和解决方案
虽然视频声音识别技术已经取得了很大的进展,但仍然面临一些挑战。本节将介绍一些常见的挑战,并提供相应的解决方案,帮助读者更好地应对这些问题。
六、视频声音识别技术的优势与劣势
视频声音识别技术有很多优势,例如速度快、准确性高、适用于多种语言等。但同时也存在一些劣势,例如对背景噪声敏感、对语音质量要求较高等。
七、视频声音识别技术的未来发展趋势
随着人工智能技术的不断发展,视频声音识别技术也将得到进一步的提升和应用。本节将展望该技术的未来发展趋势,并讨论可能的应用场景。
八、视频声音识别技术的商业化前景
视频声音识别技术在商业领域具有广阔的应用前景。本节将介绍一些可能的商业化应用场景,并讨论该技术在商业领域中的发展前景。
九、视频声音识别技术的伦理与法律问题
随着视频声音识别技术的普及,也带来了一些伦理和法律问题。本节将探讨该技术可能带来的一些问题,并提出相应的解决方案。
十、如何选择合适的视频声音识别技术
在选择视频声音识别技术时,需要考虑多个因素,例如准确性、速度、可扩展性等。本节将介绍一些选择技术的关键因素,并提供一些建议。
十一、视频声音识别技术的实际应用案例分析
通过分析一些实际应用案例,我们可以更好地理解视频声音识别技术在实际场景中的应用效果和价值。
十二、如何提高视频声音识别的准确性
视频声音识别的准确性是一个重要的指标,本节将介绍一些提高准确性的关键技巧和方法。
十三、视频声音识别技术与语音合成技术的结合
将视频声音识别技术与语音合成技术结合起来,可以实现更多有趣的应用。本节将讨论这种结合可能带来的一些应用场景。
十四、视频声音识别技术的数据安全与隐私保护
视频声音识别技术涉及大量的个人信息和语音数据,因此数据安全和隐私保护是一个重要问题。本节将介绍一些保护数据安全和隐私的关键措施。
十五、视频声音识别技术在教育领域的应用
视频声音识别技术在教育领域具有广泛的应用价值。本节将介绍该技术在教育领域中的一些应用案例,并讨论其带来的影响和改变。
视频识别声音提取文字的技术正在不断发展,并在多个领域得到广泛应用。通过视频声音识别技术,我们可以实现语音内容的可视化,提高工作效率,同时也为听力障碍人群提供了更多便利。然而,该技术仍然面临一些挑战,例如背景噪声的处理和语音质量的要求。未来,随着人工智能技术的发展,视频声音识别技术将得到进一步的提升和应用。相信通过不断地研究和创新,视频声音识别技术将为我们带来更多惊喜和便利。
以视频识别声音提取文字教程——将影像转化为文字的利器
在数字化时代,视频已经成为一种重要的信息媒介,然而,对于视频中的语音内容的提取却一直是一个具有挑战性的任务。然而,随着人工智能技术的快速发展,以视频识别声音提取文字成为了可能。本文将为您介绍一种基于视频识别声音的方法,并教您如何提取视频中的文字内容。
视频转文字技术的应用领域及意义
随着在线视频平台的兴起,对于视频中语音内容的处理和利用需求越来越高。视频转文字技术的应用领域广泛,包括但不限于:语音识别、字幕生成、智能音箱等。通过将视频中的语音内容转化为文字,不仅可以方便用户搜索、浏览和分享视频内容,还能为机器学习、自然语言处理等领域提供大量数据支持。
视频识别声音技术原理及方法
1.视频分析与处理:通过对视频进行帧提取和预处理,提取出语音帧。
2.声音信号处理:将语音帧进行语音信号处理,去除噪音、增强语音信号。
3.语音识别模型训练:利用机器学习算法和大量语音训练数据,训练出适用于视频中声音的识别模型。
4.语音识别与转换:对视频中的声音进行识别,并转化为文字。
视频识别声音提取文字的关键技术与挑战
1.声音信号处理:语音信号中常常存在噪音,需要进行有效的去噪和增强处理。
2.语言模型训练:针对不同领域和语言特点,需要构建针对性的语言模型,以提高识别准确率。
3.多说话人识别:对于多人对话的视频,需要识别和区分不同的说话人,并将其转化为相应的文字。
4.语速和口音的影响:不同说话人的语速和口音差异较大,需要适应不同说话人的语音特点,提高识别准确度。
实践案例分析:基于视频识别声音提取文字的应用实例
1.在线视频字幕生成:利用视频转文字技术,实现在线视频字幕的自动生成,提升用户体验。
2.语音内容搜索:将视频中的语音内容转化为文字,实现针对视频中具体语音内容的搜索和定位。
3.智能音箱交互:通过将视频中的声音转化为文字,智能音箱可以更好地理解用户的语音指令和需求。
发展前景与应用展望
随着人工智能技术的不断进步和应用场景的丰富,视频识别声音提取文字技术将在多个领域得到广泛应用。未来,我们有理由相信,视频转文字技术将为语音内容的处理和利用带来更大的便利和效益。
视频识别声音提取文字技术作为一种将影像转化为文字的利器,具有广泛的应用前景。通过视频转文字技术,可以方便地提取视频中的语音内容,并进行各种语音相关任务。然而,视频识别声音提取文字仍面临着一些挑战,需要进一步的研究和技术突破。但相信在不久的将来,视频转文字技术将会在我们的生活中发挥越来越重要的作用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jiezhimei.com/article-1990-1.html





最新文章
-
手机拍照时对光出现黑条闪动原因是什么?
2025-04-08 -
如何查询电脑配置和验机网址?
2025-04-08 -
电脑接电话无声音是什么原因?如何解决通话无声的问题?
2025-04-08 -

投影仪联动器有哪些优缺点?如何选择?
2025-04-08 -
投影仪推荐下载哪些软件?
2025-04-08 -

笔记本电脑通常配备哪种硬盘?如何选择合适的硬盘?
2025-04-08 -

望仙谷紫萱用手机拍照技巧是什么?如何拍出好照片?
2025-04-08 -
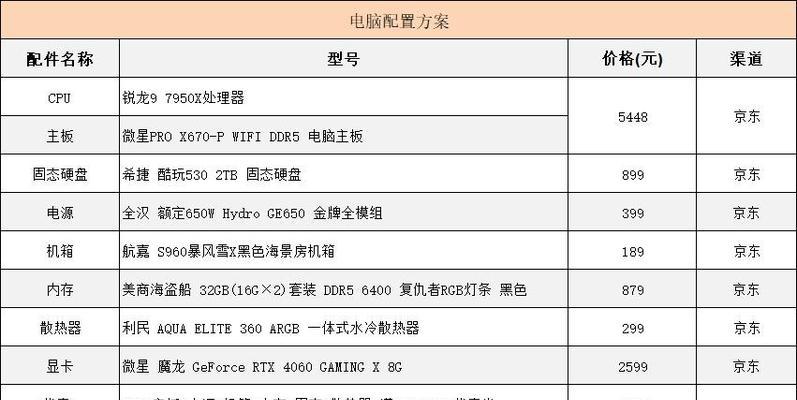
怎么看电脑配置中的显卡?识别显卡的方法是什么?
2025-04-08
热门文章
-

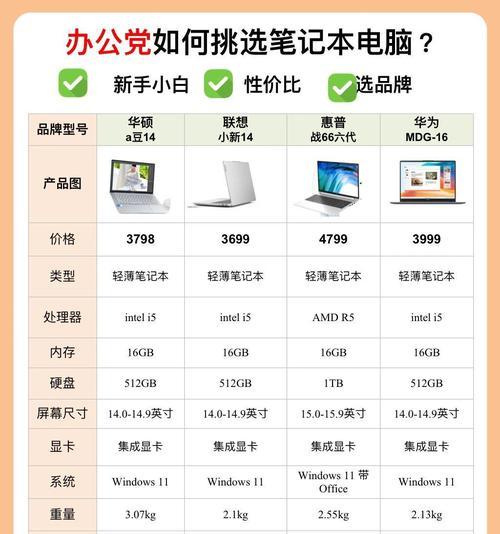
简单需求应该买什么笔记本电脑?如何选择?
2025-04-02 -

电脑中夹子图标的符号怎么输入?
2025-04-03 -
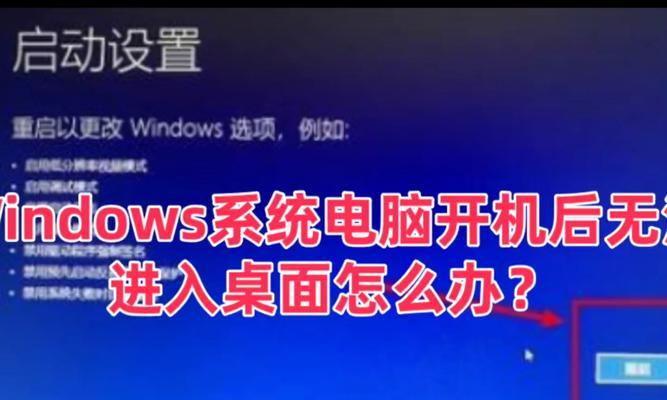
电脑开机或关机键无反应怎么办?解决方法是什么?
2025-04-03 -
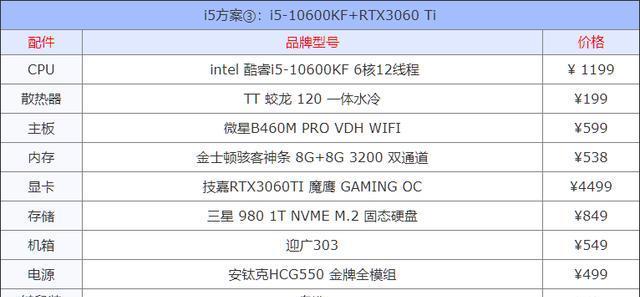
电脑组装配置错误如何纠正?有哪些调整方法?
2025-04-02 -
电脑如何通过手机共享wifi上网?
2025-04-02 -
电脑添加图标到固定栏的操作步骤是什么?
2025-04-04 -

短剧播放时电脑黑屏如何快速解决?
2025-04-05 -

水上悬浮相机如何与手机配合使用?拍照方法是什么?
2025-03-27